Omni-proactive streaming video understanding, i.e., autonomously deciding when to speak and what to say from continuous audio-visual streams, is an emerging capability of omni-modal large language models. Existing benchmarks fall short in three key aspects: they rely primarily on visual signals, adopt polling or fixed-timestamp protocols instead of true proactive evaluation, and cover only a limited range of tasks, preventing reliable assessment and differentiation of omni-proactive streaming models.
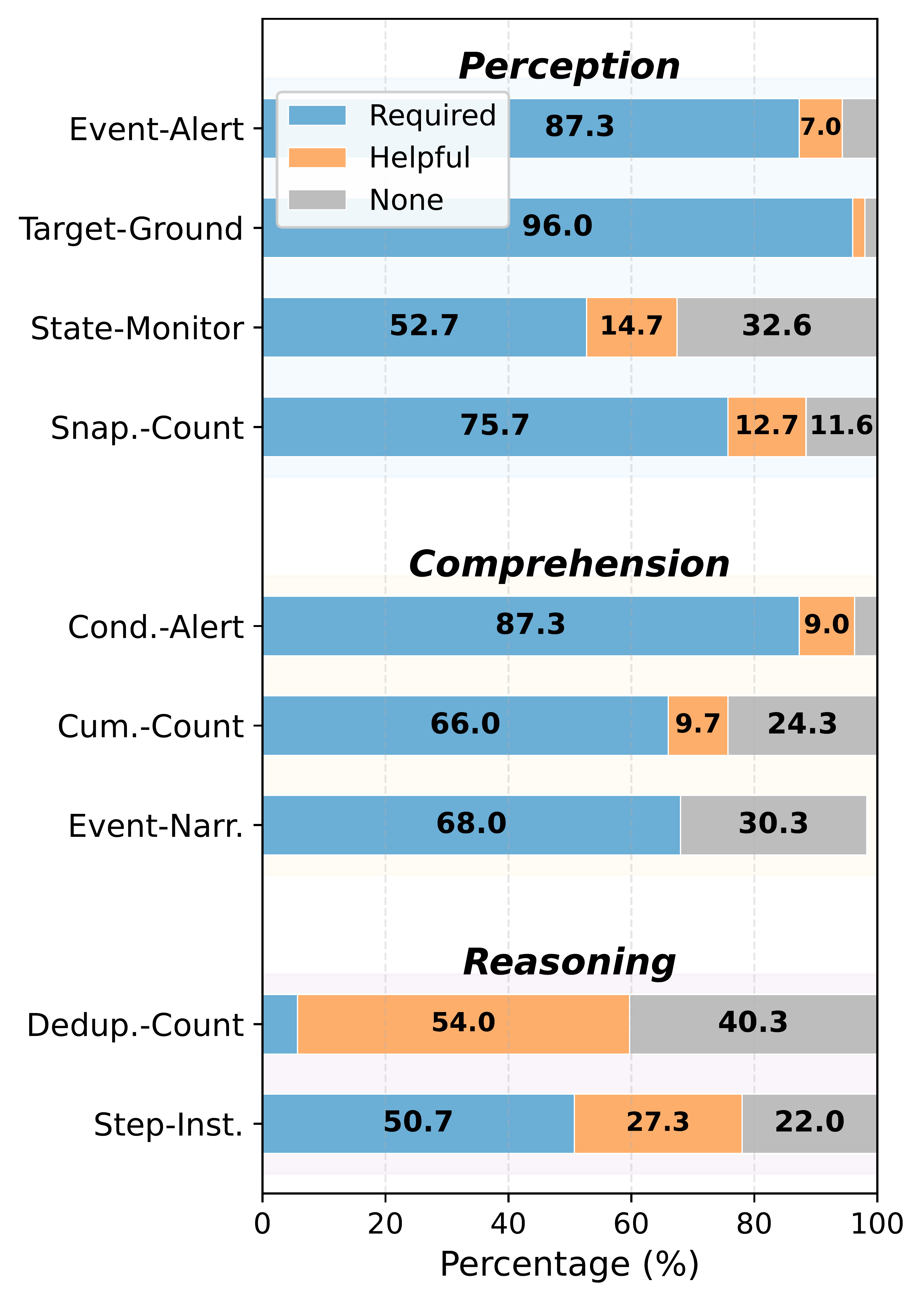
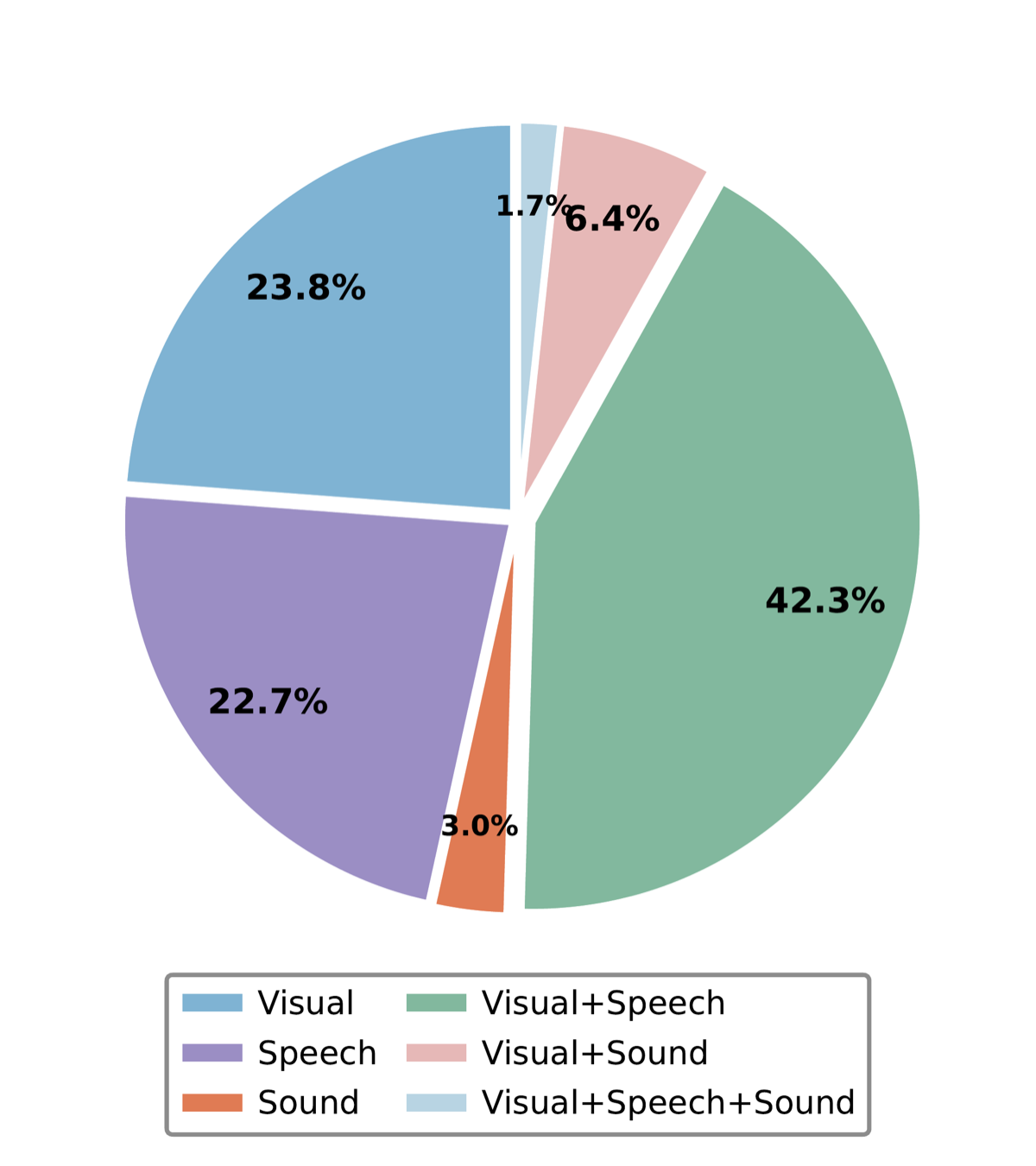
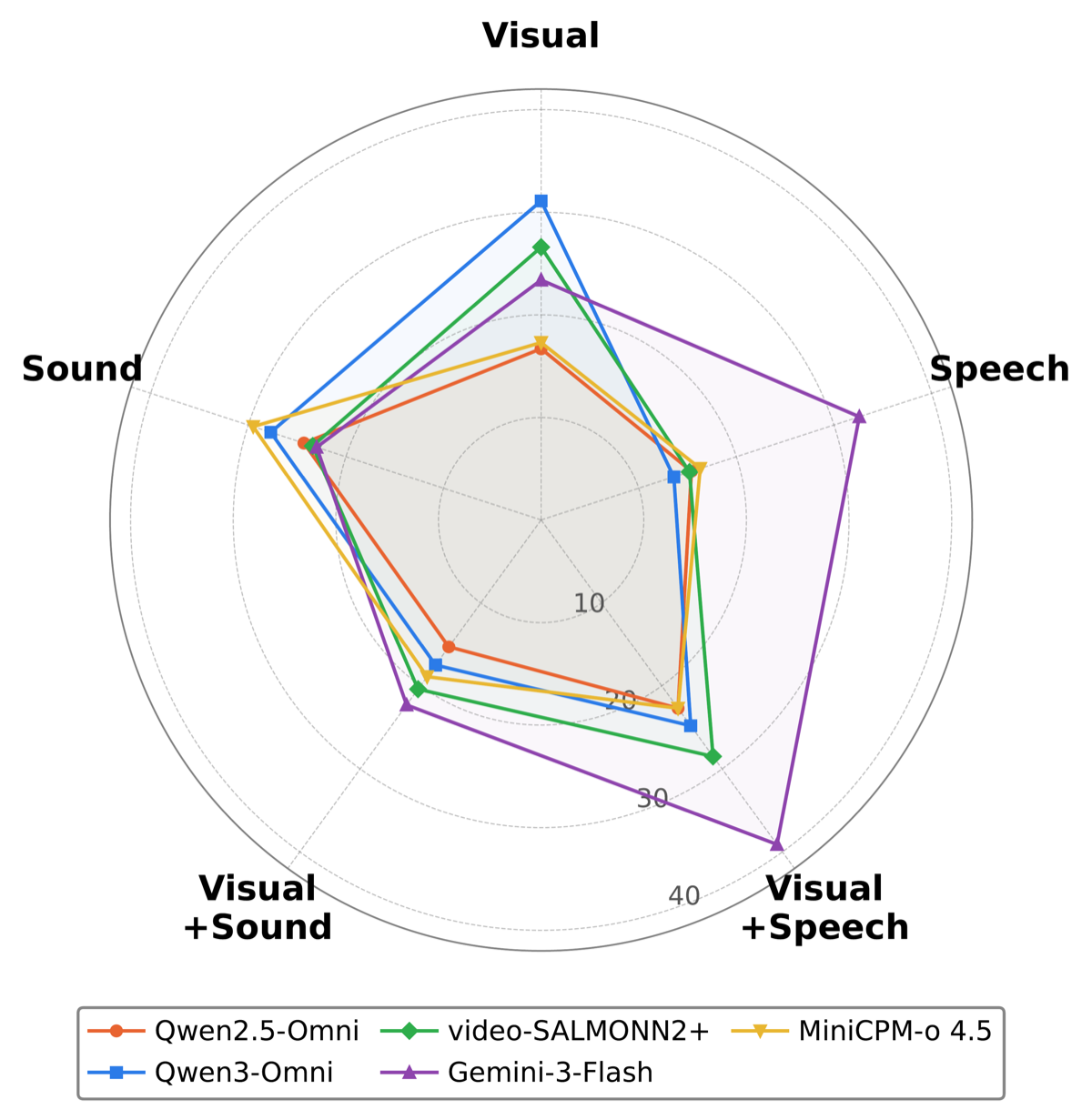
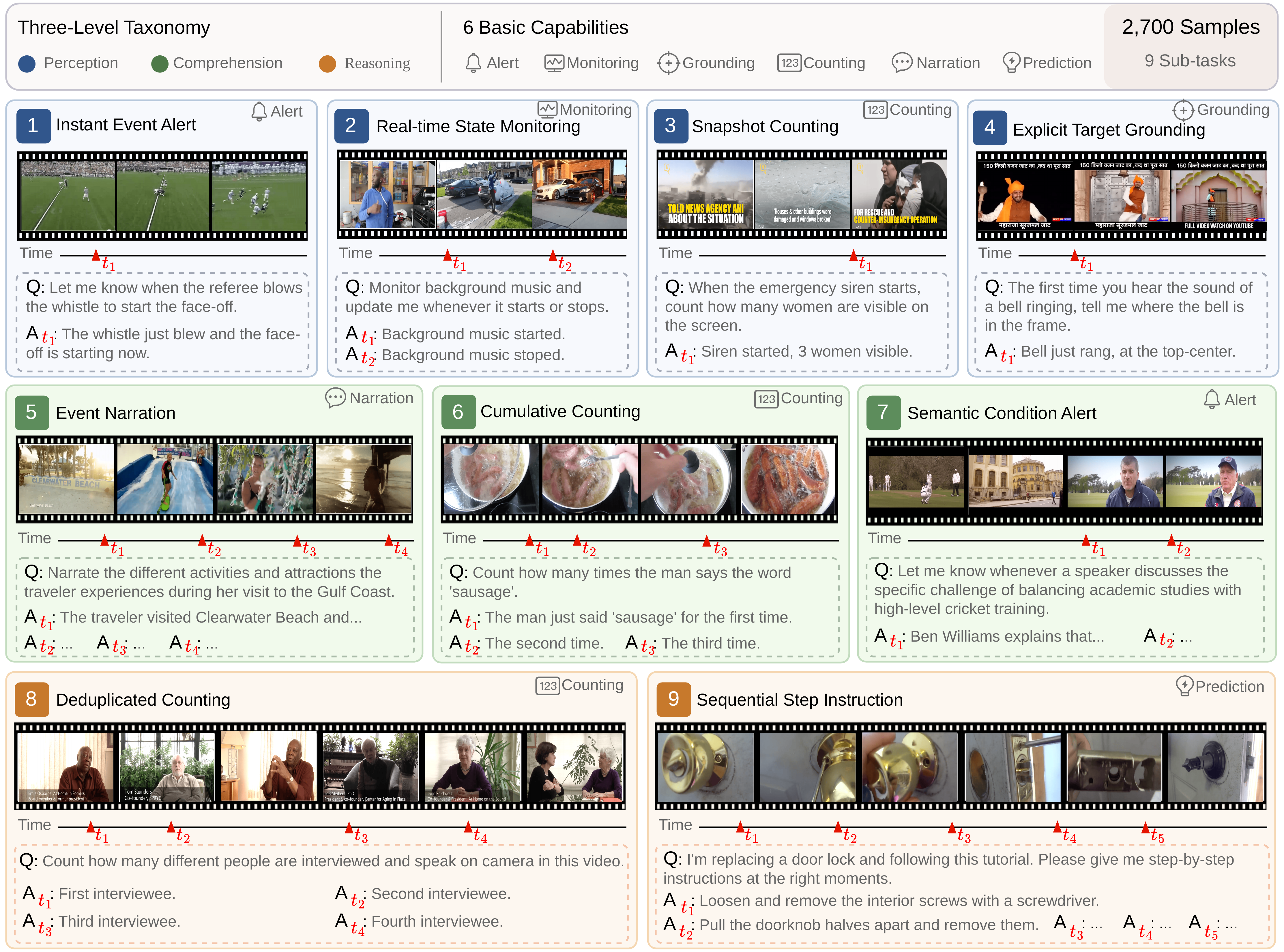
We present OmniPro, the first benchmark to jointly evaluate omni-modal perception, proactive responding, and diverse video understanding tasks. It comprises 2,700 human-verified samples spanning 9 sub-tasks and 3 cognitive levels, covering 6 basic video understanding capabilities. Notably, 84% of samples require audio signals (speech or non-speech), and each sample is annotated with modality-isolation labels to enable fine-grained multimodal analysis.
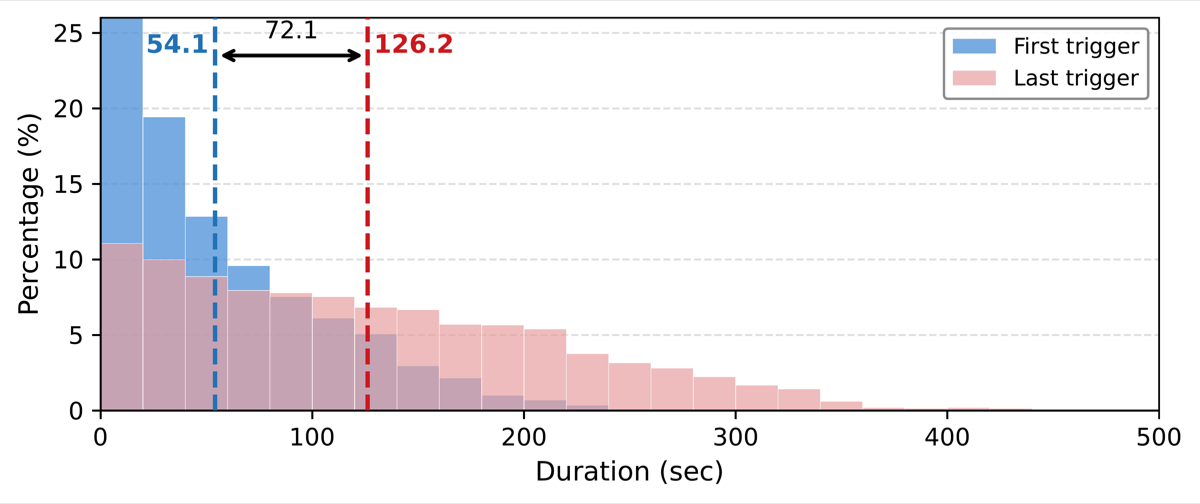
We further introduce a dual-mode evaluation protocol: Probe mode assesses content understanding by querying the model before and after each ground-truth trigger, while Online mode evaluates full proactive ability by requiring models to autonomously decide when to respond in streaming input.
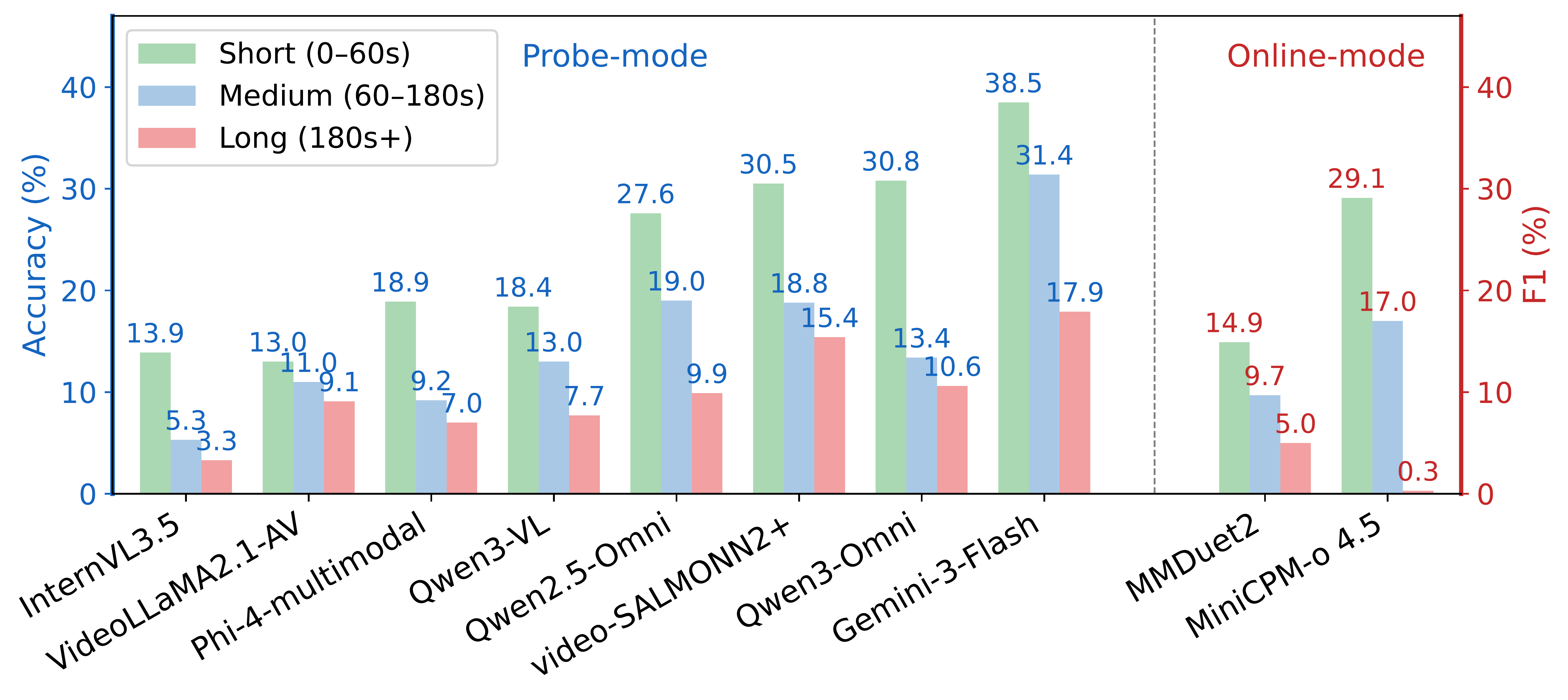
Evaluating 11 representative models reveals three key findings: (1) audio provides consistent gains but with highly variable utilization across models, (2) performance degrades significantly over time, indicating limited long-horizon robustness, and (3) non-speech audio perception remains the weakest dimension.